This post is aimed at readers who are familiar with Rust and want some insight into why it is great for machine learning.
- A machine learning problem
- Why is machine learning hard?
- What is rusty-machine?
- Where are we now?
- What’s next?
- A brief highlight of other community efforts
I will pick a particular problem that can be solved using machine learning and talk (briefly) through one solution. This isn’t intended as a tutorial on this particular technique but will instead give some context on why machine learning is difficult.
Afterwards I’ll be describing briefly the work I’ve been doing on rusty-machine. Rusty-machine is a general purpose machine learning library implemented entirely in Rust. With this post I will illustrate with examples some of the strengths of rusty-machine. This is by no means a complete summary - though I intend to cover more completely how rusty-machine is put together in future posts.
I’d love to get some feedback - both on this post and on the library.
Note: I’m planning on doing a write-up in a similar vein for those who are not so familiar with Rust.
Let’s talk about a machine learning problem
If you’re familiar with machine learning you can skip this section and go on to read about rusty-machine.
We’ll consider the problem of classifying whether a tumor is malignant or benign. Doctors use various tools to take measurements of tumors, for example the size, symmetry, compactness, etc. Using these measurements the doctor wishes to identify whether the tumor is malignant or benign so that they can take the best course of action.
This is a problem that we can address using machine learning.
“Field of study that gives computers the ability to learn without being explicitly programmed.” - Arthur Samuel
There are a number of different machine learning tools that can be used to solve this problem. We will only consider one of these tools - The Logistic Regression Model.
The high-level idea behind logistic regression is that we take a weighted sum of the tumors features and then scale this value to be between 0 and 1 - so that it can be thought of as the probability that a tumor is malignant. For example if we have measurements for the volume and the average radius of the tumor (denoted x1 and x2 respectively). Let β be the vector of weight parameters. Then our weighted sum would be given by:
xTβ = β0 + β1x1 + β2x2.
The β vector makes up the parameters of the logistic regression model. Note that here we have appended x0 = 1 to our features. This is a common practice used to model an intercept term. The method we use to scale this weighted sum is where the logistic regression model gets its name, the Logistic Function:
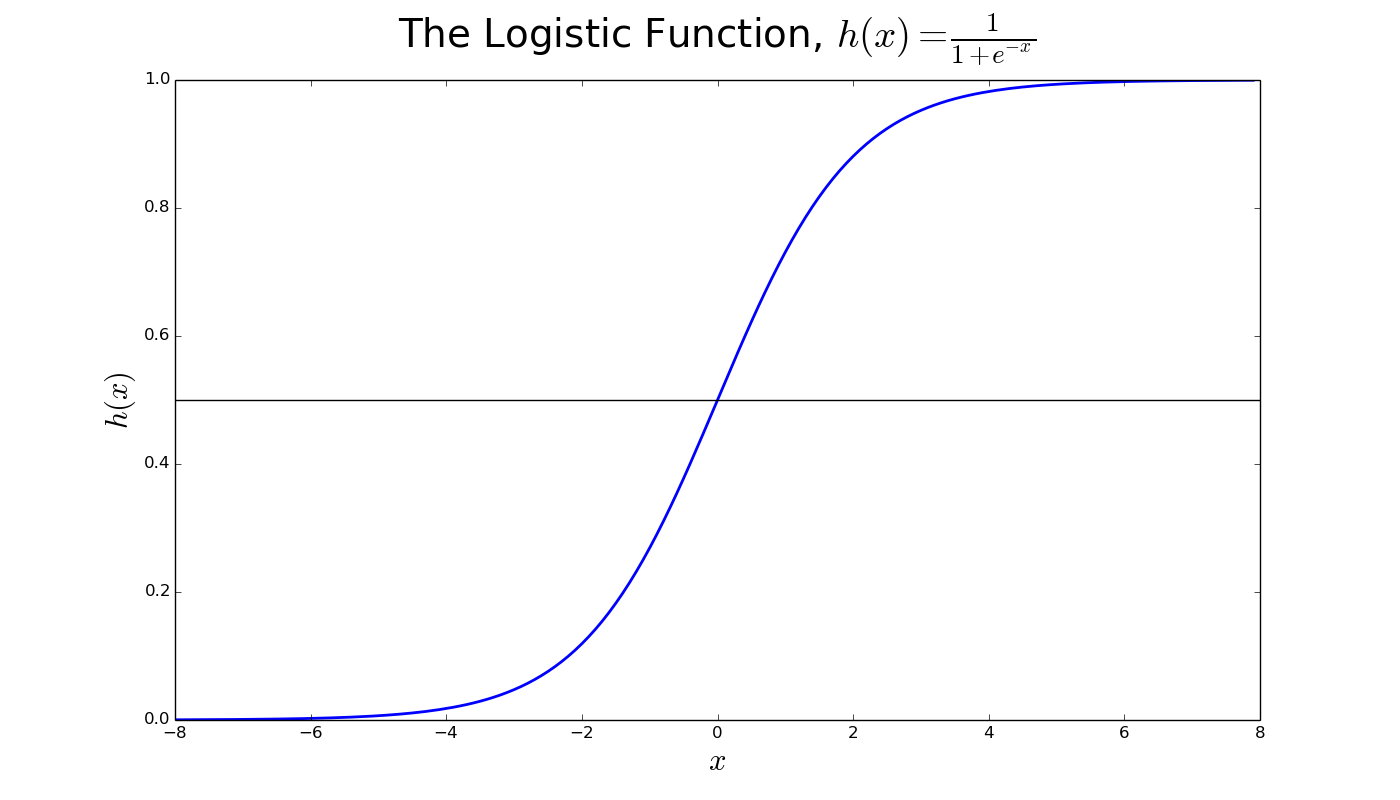
To decide whether a tumor is malignant or benign we compute h(xTβ). This tells us the probability that the tumor is malignant (greater than 0.5 suggests the tumor is likely to be malignant).
All of this is great, but we’re not learning yet. The idea behind logistic regression is that we can learn what the β vector should be based on some sample (training) data. This process is known as training the model. A common approach to doing this is through Gradient Descent optimization. This involves defining a cost function and finding the parameters which minimize this cost. I won’t go into the details here but there are plenty of great resources online.
Why is machine learning hard?
As I said above there are many different techniques we could have used to classify the tumors. Even once we have chosen a technique there are many other considerations. Which algorithm do we use to train the model? How do we construct our cost function? How do we choose the best subset of the data to represent our problem?
Machine learning comes with another challenge which is linked to the above. We often work with huge amounts of data which makes training our models take a very long time. We need our tools to emphasize performance without sacrificing the flexibility required to explore all of the different options associated with even a single model.
Rusty-machine is an attempt to solve this problem. By utilizing Rust’s high performance and high-level language features we aim to construct a framework for iterative development and speed.
Some terminology
Before we jump into rusty-machine we’ll need some terminology.
In Machine Learning we have Models. These models can be used to explain a pattern which is present in some data. The Logistic Regression model is an example of this. By giving the model some data we can train it and have it learn the underlying pattern. The model can then be used to predict new patterns from data that it hasn’t seen before.
The key take-aways are:
Model: An object representing a set of possible explanations for some data patterns.Train: The act of teaching a model the best explanation from some data (learning).Predict: Using the learned model to predict the pattern of unseen data.
Rusty-machine
Rusty-machine is a general purpose machine learning library. Implemented entirely in Rust. It is still very much in the early stages of development and so the following information is likely to be outdated in the future. I hope to provide an overview of what rusty-machine is trying to achieve.
Rusty-machine aims to provide a consistent, high-level API for users without compromising performance. This consistency is achieved through Rust’s trait system.
A consistent API
By using traits we allow users to easily implement a model with clean access to the necessary parts. We hope that we can provide the foundation of each model and make it easy for the user to choose how the learning problem is solved. This could involve choosing from a common set of techniques or alternatively plugging their own tools in. This is in contrast to some (very good) libraries which provide their flexibility through bloated APIs.
/// Trait for supervised models.
pub trait SupModel<T,U> {
/// Train the model using inputs and targets.
fn train(&mut self, inputs: &T, targets: &U);
/// Predict output from inputs.
fn predict(&self, inputs: &T) -> U;
}
The above is the trait for a specific type of model - a Supervised model. This means that the model is trained using some example outputs (called targets) as well as the inputs. There is also a trait for UnSupervised models which looks very similar (except that we do not have any targets).
When a user wants to use a model they train and predict from the model via this trait. This is the essence of our consistent API - all models are accessed via the same core methods. We balance this rigid access by allowing the models themselves to be very customisable. Let’s consider our Logistic Regression model.
pub struct LogisticRegressor<A>
where A: OptimAlgorithm<BaseLogisticRegressor>
{
base: BaseLogisticRegressor,
alg: A,
}
This looks a little messy… Here A is a generic type. The line beginning where specifies that A must implement the OptimAlgorithm trait. This is the trait for Gradient Descent algorithms (which is poorly named, my apologies!). The BaseLogisticRegressor contains the parameters, β, and other core methods for logistic regression.
The LogisticRegressor struct allows any Gradient Descent algorithm that fits the base struct to be used. There are a number of built-in algorithms (Stochastic GD, etc.) or alternatively the user can create their own and plug them in. This relationship is two-fold - developers can create their own models and utilize the existing gradient descent algorithms.
Of course this doesn’t end with logistic regression and gradient descent. This flexibility and customisation is an aim throughout rusty-machine. Let’s consider a slightly more involved example:
pub struct GenLinearModel<C: Criterion> {
parameters: Option<Vector<f64>>,
criterion: C,
}
pub trait Criterion {
type Link : LinkFunc;
/// The variance of the regression family.
fn model_variance(&self, mu: f64) -> f64;
// Some other methods ...
}
Our Criterion can be used to specify a Generalized Linear Model. We provide a link function and some other functions which are distribution dependent, and the model does the heavy lifting. Of course there are some built in Criterion, e.g. Poisson or Binomial regression. But the primary purpose of this design is to allow the user to have full control over the GLM without needing to write chunks of code to train the model in each case.
Where are we now?
Rusty-machine currently has a fairly comprehensive linear algebra library. This certainly isn’t state of the art but it is working well enough (for now…). The linear algebra library also provides some common data manipulation methods.
In terms of machine learning the library is growing and will continue to do so. Currently there is support for:
- Linear Regression
- Logistic Regression
- Generalized Linear Models
- K-Means Clustering
- Neural Networks
- Gaussian Process Regression
- Support Vector Machines
All of the above aim to provide a wealth of customisation. For example, different kernels for GPs, different cost and activation functions for Neural Networks, and more. In addition to those that are built-in it is also easy to create your own kernels/cost functions and use these within the existing models.
Next steps
There is definitely room for improvement on existing algorithms - both for performance and introducing some more modern techniques. There will also need to be:
- Some restructuring of the current library.
- Separation of linear algebra into a new crate.
- Addition of data tools.
Among other things.
In the slightly more distant future we’ll need to decide how to proceed with the linear algebra as well. This will most likely mean using bindings to BLAS and LAPACK - probably via some central community adopted linear algebra library.
The down sides
Maybe this is all sounding great. However, it is still early days and lot’s of work still needs to be done. We haven’t met our goal of complete flexibility and it will be a while before we do.
I think the vision is strong but we’re a long way off and lack a lot of key components for a Machine Learning library. Consistent data handling, visualizations and performance are all core areas that need a lot of work. Even after this many would consider validation and pipelines too important to miss.
I said above that rusty-machine is implemented entirely in Rust. Although this is certainly a positive in a lot of ways there is definitely the need to introduce some foreign language libraries. It will be very difficult to match the performance and care that has gone into many scientific libraries: libsvm, LAPACK, BLAS and many others.
I’d be naive also to ignore the fact that I have been the sole developer on this project for a while*. There’s likely some bad choices that seem good to me - I’d love to have those pointed out!
* I have had some help in places. Thanks raulsi and all of the amazing people at /r/rust and SO!
Call for help
Rusty-Machine is an open-source project and is always looking for more people to jump in. If anything in this post has stood out to you please check out the collaborating page.
I should also emphasize that the project doesn’t just need people with machine learning expertise. There is a need for work on data handling and loading, visualizations, and other things. Even within the machine learning parts it would certainly help if some Rust experts helped out with optimizations.
Rust sounds cool… But rusty-machine not so much
Rusty-machine isn’t the only machine learning tool written in Rust. There are other libraries and tools which you should take a look at.
And lots of others.